Hashing for large scale similarity
Similarity computation is a very common task in real-world machine learning and data mining problems such as recommender systems, spam detection, online advertising etc. Consider a tweet recommendation problem where one has to find tweets similar to the tweet user previously clicked. This problem becomes extremely challenging when there are billions of tweets created each day.
In this post, we will discuss the two most common similarity metric, namely Jaccard similarity and Cosine similarity; and Locality Sensitive Hashing based approximation of those metrics.
Jaccard Similarity
Jaccard similarity is one of the most popular metrics used to compute the similarity between two sets. Given set $A$ and $B$, jaccard similarity is defined as
$$\begin{aligned} jaccard(A, B) = \frac{| A \cap B | }{| A \cup B|} \end{aligned}$$Let's define tweet as
$$\begin{aligned} t_1 = \{u_1, u_2\} \\ t_2 = \{u_2, u_3, u_4\} \end{aligned}$$where each tweet is represented by a set of users who clicked the tweet. The jaccard similarity between $t_1$ and $t_2$ is given by
$$\begin{aligned} jaccard(t_1, t_2) = \frac{ 1 }{4} \end{aligned}$$Cosine similarity
Cosine similarity is a vector space metric where similarity between two vector $\vec{a}$ and $\vec{b}$ is defined as $cosine(\vec{a}, \vec{b}) = \frac{ \langle \vec{a}, \vec{b} \rangle }{\|\vec{a}\| \|\vec{b}\|}$ where, $\langle . \rangle$ is a dot product and $\| .\|$ is $L_2$ norm operator.
Jaccard similarity ignores the weights as it's a set based distance metric for e.g. number of user clicks. Lets define
$$\begin{aligned} t_1 & = \{u_1 =2, u_2=1\} \\ t_2 & = \{u_2=2, u_3=8, u_4=3\} \end{aligned}$$where the number indicates the number of times user $u$ clicked tweet $t$. Now, the tweets can be represented in user's vector space as
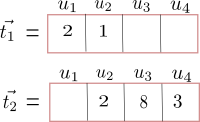
and the cosine similarity is given as
$$cosine(\vec{t_1}, \vec{t_2}) = \frac{ \langle \vec{t_1}, \vec{t_2} \rangle }{\|\vec{t_1}\| \|\vec{t_2}\|} = \frac{2}{\sqrt{(5) * (77)}} = 0.1019$$Limitations
Pairwise similarity scales quadratically $\Theta(n^2)$ both in terms of time and space complexity. Hence, finding similar items is very challenging for a large number of items. In the following section, we discuss locality sensitive hashing to address these limitations.
Locality Sensitive Hashing (LSH)
Hashing is a very widely used technique that assigns pseudo-random value/bucket to objects. Hash functions must be uniform i.e. each bucket is equally likely. Locality Sensitive Hashing(LSH) is a hashing based dimensionality reduction method that preserves item similarity. More precisely, LSH hashes items to $k$ buckets such that similar items map to the same bucket with high probability. Such hash signatures can be used for efficient neighborhood search as well as to compute similarity between items on the fly.
Minhash
First, lets define
$$\begin{aligned} U & = |t_1 \cup t_2| \Rightarrow \lbrace u_1, u_2, u_3, u_ 4\rbrace\\ S \subset U & = |t_1 \cap t_2| \Rightarrow \lbrace u_2\rbrace \\ |U| & = n \Rightarrow 4\\ |S| &= d \Rightarrow 1 \\ k & \text{ be the dimensionality of hashing} \\ & \ \ \ \ \ \ \text{i.e number of hash functions} \end{aligned}$$Let $h(*) \in f(*)\rightarrow N$ be a hash function that maps an object to a positive integer. The minhash is defined as
$$\begin{aligned} minhash_h(t = \lbrace u_1, u_2...\rbrace) = argmin_u \ h(u_i) \end{aligned}$$a function that returns the item with smallest hash value. Now, a k-dimensional minhash signature is defned by $k$ hash functions
$$\begin{aligned} \lbrace minhash_{h_1}, minhash_{h_2}, ...., minhash_{h_k}\rbrace \end{aligned}$$Given $k\text{-}minhash(t)$, jaccard similarity of item $t_1$ & $t_2$ is defined as
$$\begin{aligned} jaccard(t_1, t_2) & = P\lbrack minhash(t_1) = minhash(t_2)\rbrack \\ & \approx \frac{\sum_{i}^{} \text{1} \lbrack k\text{-}minhash(t_1)_i = k\text{-}minhash(t_2)_i \rbrack}{k} \end{aligned}$$where $1\lbrack . \rbrack$ is an indicator function.

Minhash explained
Although theoretical proof is quite rigorous, the key idea is very intuitive. First, let's define,
a) How many ways can we shuffle $U$ such that $u_2$ is the first element?
Ans: 3!
b) More generally, how many ways can we shuffle $U$ such that $u \in S$ is the first element?
Ans: $d \times (n-1)!$
Hashing a set of items is equivalent to generating a random permutation of the set. So, $minhash_h(t_1) = minhash_h(t_2)$, only if the hash function $h$ assigns smallest value to $u \in S$ i.e $u_2$. From this observation, we can conclude
$$\begin{aligned} P\lbrack minhash_h(t_1) = minhash_h(t_2)\rbrack = & \frac{d(n-1)!}{n!} \\ = & \ \ \frac{d}{n} \\ = & \frac{|S|}{|U|} \\ = & \frac{|t_1 \cap t_2|}{|t_1 \cup t_2|}, \ \text{voila!!} \end{aligned}$$Hence, minhash approximates jaccard similarity.
Simhash
Let $\vec{h_i}$ be a random vector passing through origin. Let's define a simhash function for tweet $t$
$$\begin{aligned} simhash_{\vec{h}}(\vec{t}) = sgn(\langle \vec{t}, \vec{h} \rangle) \end{aligned}$$where,
$$\begin{aligned} sgn(x) = \begin{cases} 1 & \text{ if } x \gt 0 \\ 0 & \text{ if } x = 0 \\ -1 & \text{ if } x \lt 0 \end{cases} \end{aligned}$$Given simhash, $k\text{-}simhash$ can be defined as
$$\begin{aligned} k\text{-}simhash(t) = \lbrack simhash_{\vec{h_1}}(\vec{t}), simhash_{\vec{h_2}}(\vec{t}) ....., simhash_{\vec{h_k}}(\vec{t})\rbrack \end{aligned}$$Now, the angle between $t_1$ and $t_2$ is defined as
$$\begin{aligned} \theta & = (1 - P\lbrack simhash_h(t_1) = simhash_h(t_2)\rbrack) \times \pi \\ & \approx (1- \frac{\sum_{i=1}^{} \text{1} \lbrack simhash_{\vec{h_i}}(\vec{t_1}) = simhash_{\vec{h_i}}(\vec{t_2}) \rbrack}{k}) \times \pi \end{aligned}$$
Simhash explained
In this section, we discuss the intuition behind approximation of cosine similarity using simhash.

In the figure above, for the vector $\vec{t}$, the pink shaded area corresponds to the half-space where $simhash_{\vec{*}}(\vec{t}) \gt 0$, for eg. $simhash_{\vec{h_1}}(\vec{t})$. On the other hand, the white region corresponds to the half-space where $simhash_{\vec{*}}(\vec{t}) \lt 0$, for eg. $simhash_{\vec{h_2}}(\vec{t})$

Lets consider two vector $\vec{t_1}$, $\vec{t_2}$ and $\theta$ is an angle between them as shown in figure above. For a randomly drawn a vector $\vec{h}$ passing through origin
$$\begin{aligned} \lbrack simhash_h(t_1) = simhash_h(t_2)\rbrack \end{aligned}$$is true only if vector $\vec{h}$ lies in purple or white shaded area (i.e other than pink and blue shaded area). From this observation, we can define
$$\begin{aligned} P\lbrack simhash_h(t_1) = simhash_h(t_2)\rbrack & = (1 - \frac{\text{total angle corresponding to blue or pink region}}{2 \times \pi})\\ & = (1 - \frac{\theta}{\pi})\\ \theta & = ( 1 - P\lbrack simhash_h(t_1) = simhash_h(t_2)\rbrack) \times \pi , \ \text{voila!!} \end{aligned}$$Hence, simhash approximates cosine similarity.
In the next post, I will discuss more about implementation of minhash and simhash.
Cite this post:
@article{sedhain2019hashing,
title = {Hashing for Large Scale Similarity},
author = {Sedhain, Suvash},
journal = {ssedhain.com},
year = {2019},
month = {Jan},
url = {https://mesuvash.github.io/blog/2019/Hashing-for-similarity/}
}